
Z-Image-Turbo-GGUF 低显存GGUF模型使用和工作流
- 2026-01-19
- 阅读:1625
Z-Image-Turbo – Z-Image 的蒸馏版本,仅需 8 次函数评估(NFEs) 即可达到或超越主流竞品性能。在企业级 H800 GPU 上可实现 ⚡️亚秒级推理延迟⚡️,并可在 16G 显存的消费级设备 上轻松运行。该模型在逼真图像生成、双语文本渲染(英文与中文)以及指令遵循能力方面表现出色。

GGUF 是一种专门给本地大模型(LLM)做压缩和加速的文件格式,让模型可以在 更小的显存 / 内存 下运行,尤其适用于:
- Windows / macOS / Linux 本地推理
- CPU 运行(非常强)
- 小显存 GPU(4GB、8GB、12GB)
这次主要是需要用到下面两个项目:
Z-Image-Turbo-GGUFQwen3-4B-GGUF
最核心的 Z-Image-Turbo-GGUF 的模型

GGUF 应该选择哪个量化版本
选择GGUF量化版本需根据硬件资源、性能需求和精度要求进行权衡。以下是基于当前主流版本的选型建议:
核心版本推荐
追求最佳平衡:推荐 q4_k_m 或 q5_k_m
q4_k_m:4-bit混合量化,对关键层(如Attention)采用更高位宽,精度损失仅3-5%,内存占用适中,是大多数CPU/GPU设备(如笔记本、中端显卡)的首选,兼顾速度与质量。
q5_k_m:5-bit混合量化,精度损失进一步降低至1-3%,更接近FP16水平,适合对生成质量要求较高的场景(如专业设计、内容创作),推荐在高端GPU或服务器上使用。
追求极致精度:选择 q6_k 或 q8_0
q6_k:6-bit量化,精度损失极小(0.5-1%),接近无损,适合医疗、金融等高敏感领域。
q8_0:8-bit量化,精度几乎无损(<0.5%),是质量要求最高的专业场景(如商业图像生成、高精度文本推理)的理想选择,但显存需求较高(推荐16GB以上)。
资源极度受限:选择 q2_k 或 q3_k_m
q3_k_m:3-bit混合量化,内存占用低,适合移动端、边缘设备或老旧硬件,精度损失中等(5-8%),可接受基础推理任务。
q2_k:2-bit量化,压缩率最高,仅适用于存储和内存极有限的嵌入式设备,精度损失较大,仅作最后选择。
选型决策流程
- 显存/内存充足(≥16GB)且追求质量 → 选 q8_0 或 q6_k。
- 中等配置(8-12GB显存)或通用场景 → 选 q5_k_m(高精度)或 q4_k_m(平衡型)。
- 低配设备(<8GB显存)或移动端 → 选 q3_k_m。
- 需要极致压缩或快速加载 → 选 q4_k_m(在4-bit中精度最优)。
注意:不同模型的量化效果存在差异,建议在实际部署前,用真实数据测试不同版本的推理速度、内存占用和输出质量,以做出最优选择。
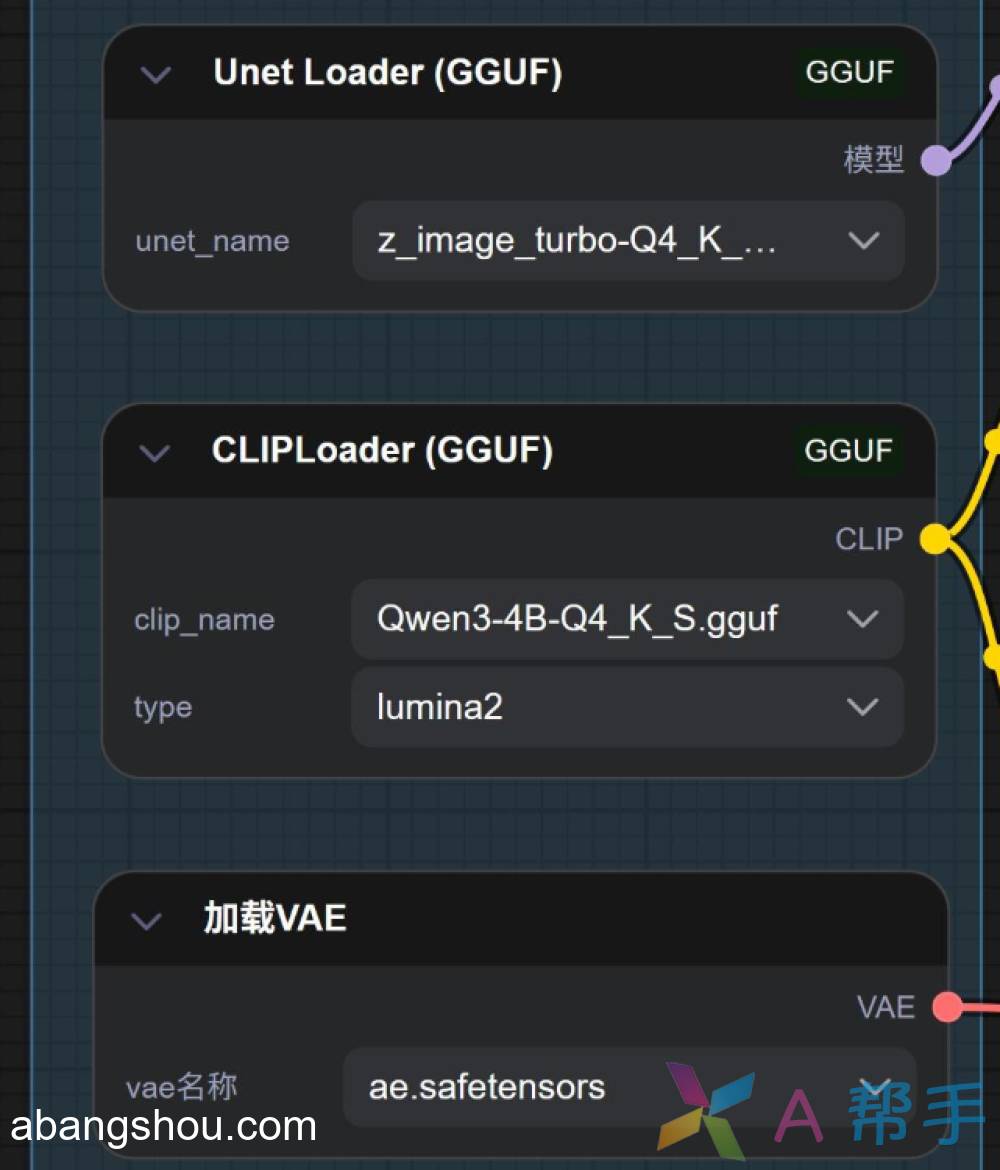
我一般从性价比角度会选 Q4_K_M 模型,这个模型的体积只有 Z-Image 官方模型的一半,比 FP8 也要小很多。另外会用到一个 Qwen-4B 的 CLIP 模型
安装 GGUF 的节点插件
GGUF 模型,必须要专门的 GGUF 节点,所以需要安装一下节点插件。
https://github.com/city96/ComfyUI-GGUF
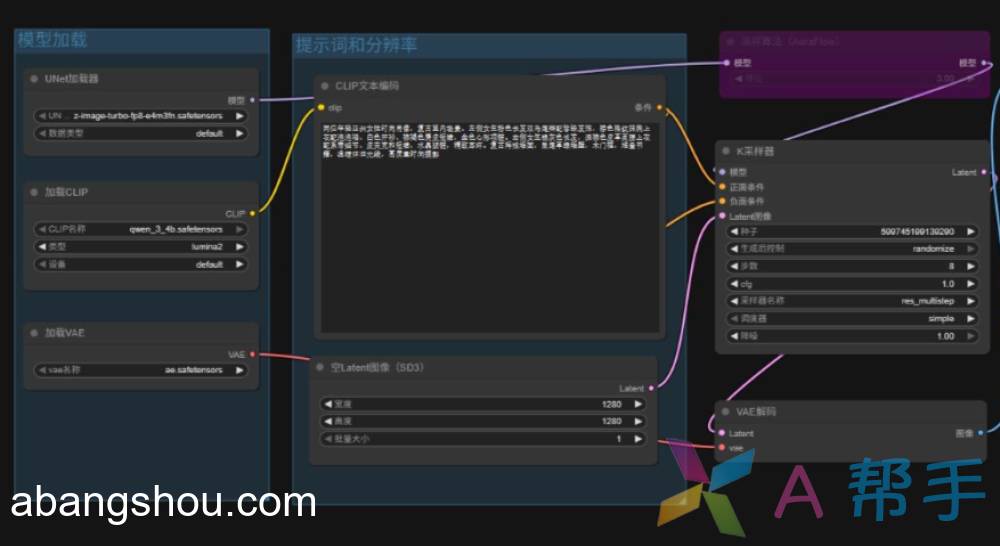
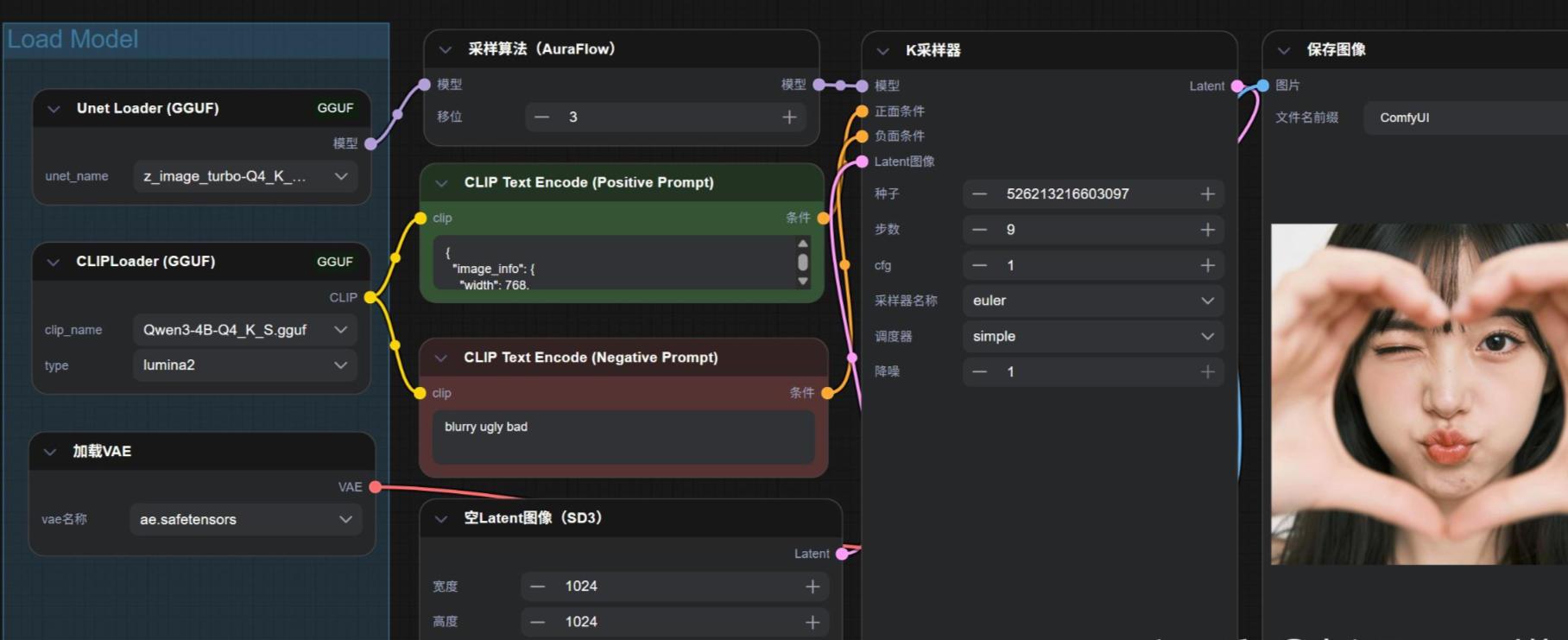
工作流参考
部分评论